pycrostates.cluster.ModKMeans#
- class pycrostates.cluster.ModKMeans(n_clusters, n_init=100, max_iter=300, tol=1e-06, random_state=None)[source]#
Modified K-Means clustering algorithm.
See Pascual-Marqui et al.[1] for additional information.
- Parameters:
- n_clusters
int The number of clusters, i.e. the number of microstates.
- n_init
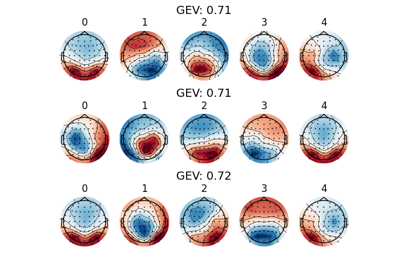
int Number of time the k-means algorithm is run with different centroid seeds. The final result will be the run with the highest Global Explained Variance (GEV).
- max_iter
int Maximum number of iterations of the K-means algorithm for a single run.
- tol
float Relative tolerance with regards estimate residual noise in the cluster centers of two consecutive iterations to declare convergence.
- random_state
None|int| instance ofRandomState A seed for the NumPy random number generator (RNG). If
None(default), the seed will be obtained from the operating system (seeRandomStatefor details), meaning it will most likely produce different output every time this function or method is run. To achieve reproducible results, pass a value here to explicitly initialize the RNG with a defined state.
- n_clusters
References
- Attributes:
GEV_Global Explained Variance.
cluster_centers_Fitted clusters (the microstates maps).
cluster_namesName of the clusters.
compensation_gradeThe current gradient compensation grade.
fittedFitted state.
fitted_dataData array used to fit the clustering algorithm.
infoInfo instance with the channel information used to fit the instance.
labels_Microstate label attributed to each sample of the fitted data.
max_iterMaximum number of iterations of the k-means algorithm for a run.
n_clustersNumber of clusters (number of microstates).
n_initNumber of k-means algorithms run with different centroid seeds.
random_stateRandom state to fix seed generation.
tolRelative tolerance to reach convergence.
Methods
copy([deep])Return a copy of the instance.
fit(inst[, picks, tmin, tmax, ...])Compute cluster centers.
get_channel_types([picks, unique, only_data_chs])Get a list of channel type for each channel.
Get a DigMontage from instance.
invert_polarity(invert)Invert map polarities.
plot([axes, show_gradient, gradient_kwargs, ...])Plot cluster centers as topographic maps.
predict(inst[, picks, factor, ...])rename_clusters([mapping, new_names])Rename the clusters.
reorder_clusters([mapping, order, template])Reorder the clusters of the fitted model.
save(fname)Save clustering solution to disk.
set_montage(montage[, match_case, ...])Set EEG/sEEG/ECoG/DBS/fNIRS channel positions and digitization points.
- __contains__(ch_type)#
Check channel type membership.
- Parameters:
- ch_type
str Channel type to check for. Can be e.g.
'meg','eeg','stim', etc.
- ch_type
- Returns:
- in
bool Whether or not the instance contains the given channel type.
- in
Examples
Channel type membership can be tested as:
>>> 'meg' in inst True >>> 'seeg' in inst False
- copy(deep=True)#
Return a copy of the instance.
- fit(inst, picks='eeg', tmin=None, tmax=None, reject_by_annotation=True, n_jobs=1, *, verbose=None)[source]#
Compute cluster centers.
- Parameters:
- inst
Raw|Epochs|ChData MNE
Raw,EpochsorChDataobject from which to extract cluster centers.- picks
str|list|slice|None Channels to include. Note that all channels selected must have the same type. Slices and lists of integers will be interpreted as channel indices. In lists, channel name strings (e.g.
['Fp1', 'Fp2']) will pick the given channels. Can also be the string values“all”to pick all channels, or“data”to pick data channels."eeg"(default) will pick all eeg channels. Note that channels ininfo['bads']will be included if their names or indices are explicitly provided.- tmin
float Start time of the raw data to use in seconds (must be >= 0).
- tmax
float End time of the raw data to use in seconds (cannot exceed data duration).
- reject_by_annotation
bool Whether to omit bad segments from the data before fitting. If
True(default), annotated segments whose description begins with'bad'are omitted. IfFalse, no rejection based on annotations is performed.Has no effect if
instis not amne.io.Rawobject.- n_jobs
int|None The number of jobs to run in parallel. If
-1, it is set to the number of CPU cores. Requires thejoblibpackage.None(default) is a marker for ‘unset’ that will be interpreted asn_jobs=1(sequential execution) unless the call is performed under ajoblib.parallel_configcontext manager that sets another value forn_jobs.- verbose
int|str|bool|None Sets the verbosity level. The verbosity increases gradually between
"CRITICAL","ERROR","WARNING","INFO"and"DEBUG". If None is provided, the verbosity is set to"WARNING". If a bool is provided, the verbosity is set to"WARNING"for False and to"INFO"for True.
- inst
- get_channel_types(picks=None, unique=False, only_data_chs=False)#
Get a list of channel type for each channel.
- Parameters:
- picks
str| array_like |slice|None Channels to include. Slices and lists of integers will be interpreted as channel indices. In lists, channel type strings (e.g.,
['meg', 'eeg']) will pick channels of those types, channel name strings (e.g.,['MEG0111', 'MEG2623']will pick the given channels. Can also be the string values “all” to pick all channels, or “data” to pick data channels. None (default) will pick all channels. Note that channels ininfo['bads']will be included if their names or indices are explicitly provided.- unique
bool Whether to return only unique channel types. Default is
False.- only_data_chs
bool Whether to ignore non-data channels. Default is
False.
- picks
- Returns:
- channel_types
list The channel types.
- channel_types
- get_montage()#
Get a DigMontage from instance.
- Returns:
- montage
None|str|DigMontage A montage containing channel positions. If a string or
DigMontageis specified, the existing channel information will be updated with the channel positions from the montage. Valid strings are the names of the built-in montages that ship with MNE-Python; you can list those viamne.channels.get_builtin_montages(). IfNone(default), the channel positions will be removed from theInfo.
- montage
- invert_polarity(invert)#
Invert map polarities.
- Parameters:
Notes
Operates in-place.
Inverting polarities has no effect on the other steps of the analysis as polarity is ignored in the current methodology. This function is only used for tuning visualization (i.e. for visual inspection and/or to generate figure for an article).
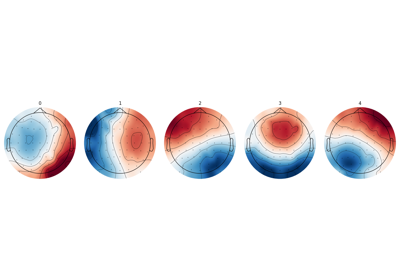
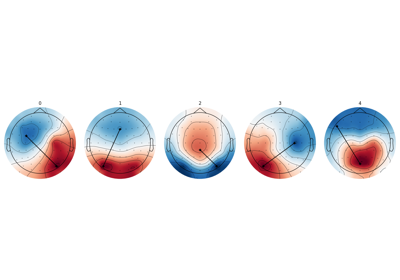
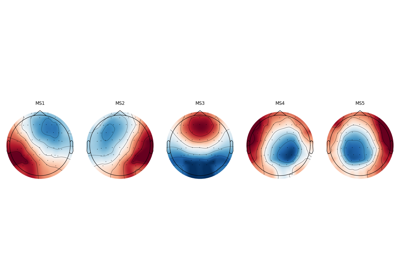
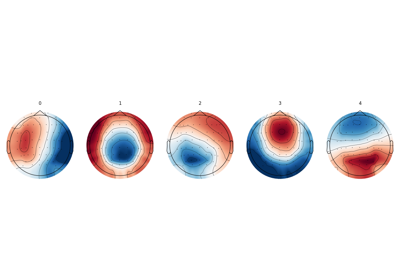
- plot(axes=None, show_gradient=False, gradient_kwargs={'color': 'black', 'linestyle': '-', 'marker': 'P'}, *, block=False, show=None, verbose=None, **kwargs)#
Plot cluster centers as topographic maps.
- Parameters:
- axes
Axes|None Either
Noneto create a new figure or axes (or an array of axes) on which the topographic map should be plotted. If the number of microstates maps to plot is≥ 1, an array of axes of sizen_clustersshould be provided.- show_gradient
bool If True, plot a line between channel locations with highest and lowest values.
- gradient_kwargs
dict Additional keyword arguments passed to
matplotlib.axes.Axes.plot()to plot gradient line.- block
bool Whether to halt program execution until the figure is closed.
- show
bool|None If True, the figure is shown. If None, the figure is shown if the matplotlib backend is interactive.
- verbose
int|str|bool|None Sets the verbosity level. The verbosity increases gradually between
"CRITICAL","ERROR","WARNING","INFO"and"DEBUG". If None is provided, the verbosity is set to"WARNING". If a bool is provided, the verbosity is set to"WARNING"for False and to"INFO"for True.- **kwargs
Additional keyword arguments are passed to
mne.viz.plot_topomap().
- axes
- Returns:
- f
Figure Matplotlib figure containing the topographic plots.
- f
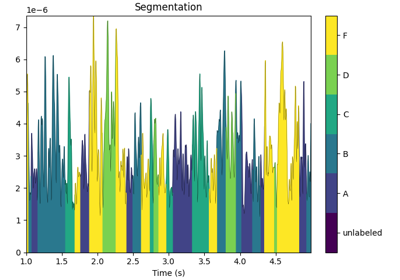
- predict(inst, picks=None, factor=0, half_window_size=1, tol=1e-05, min_segment_length=0, reject_edges=True, reject_by_annotation=True, *, verbose=None)#
Segment
RaworEpochsinto microstate sequence.Segment instance into microstate sequence using the segmentation smoothing algorithm[1].
- Parameters:
- inst
Raw|Epochs MNE
RaworEpochsobject containing the data to use for prediction.- picks
str|list|slice|None Channels to include. Note that all channels selected must have the same type. Slices and lists of integers will be interpreted as channel indices. In lists, channel name strings (e.g.
['Fp1', 'Fp2']) will pick the given channels. Can also be the string values“all”to pick all channels, or“data”to pick data channels.None(default) will pick all channels used during fitting (e.g.,self.info['ch_names']). Note that channels ininfo['bads']will be included if their names or indices are explicitly provided.- factor
int Factor used for label smoothing.
0means no smoothing. Default to 0.- half_window_size
int Number of samples used for the half window size while smoothing labels. The half window size is defined as
window_size = 2 * half_window_size + 1. It has no effect iffactor=0(default). Default to 1.- tol
float Convergence tolerance.
- min_segment_length
int Minimum segment length (in samples). If a segment is shorter than this value, it will be recursively reasigned to neighbouring segments based on absolute spatial correlation.
- reject_edges
bool If
True, set first and last segments to unlabeled.- reject_by_annotation
bool Whether to omit bad segments from the data before fitting. If
True(default), annotated segments whose description begins with'bad'are omitted. IfFalse, no rejection based on annotations is performed.Has no effect if
instis not amne.io.Rawobject.- verbose
int|str|bool|None Sets the verbosity level. The verbosity increases gradually between
"CRITICAL","ERROR","WARNING","INFO"and"DEBUG". If None is provided, the verbosity is set to"WARNING". If a bool is provided, the verbosity is set to"WARNING"for False and to"INFO"for True.
- inst
- Returns:
- segmentation
RawSegmentation|EpochsSegmentation Microstate sequence derivated from instance data. Timepoints are labeled according to cluster centers number:
0for the first center,1for the second, etc..-1is used for unlabeled time points.
- segmentation
References
- rename_clusters(mapping=None, new_names=None)#
Rename the clusters.
- Parameters:
Notes
Operates in-place.
- reorder_clusters(mapping=None, order=None, template=None)#
Reorder the clusters of the fitted model.
Specify one of the following arguments to change the current order:
mapping: a dictionary that maps old cluster positions to new positions,order: a 1D iterable containing the new order,template: a fitted clustering algorithm used as a reference to match the order.
Only one argument can be set at a time.
- Parameters:
- mapping
dict Mapping from the old order to the new order. key: old position, value: new position.
- order
listofint|tupleofint|arrayofint 1D iterable containing the new order. Positions are 0-indexed.
- templateCluster
Fitted clustering algorithm use as template for ordering optimization. For more details about the current implementation, check the
pycrostates.cluster.utils.optimize_order()documentation.
- mapping
Notes
Operates in-place.
- save(fname)[source]#
Save clustering solution to disk.
- Parameters:
- fnamepath-like
Path to the
.fiffile where the clustering solution is saved.
- set_montage(montage, match_case=True, match_alias=False, on_missing='raise', verbose=None)#
Set EEG/sEEG/ECoG/DBS/fNIRS channel positions and digitization points.
- Parameters:
- montage
None|str|DigMontage A montage containing channel positions. If a string or
DigMontageis specified, the existing channel information will be updated with the channel positions from the montage. Valid strings are the names of the built-in montages that ship with MNE-Python; you can list those viamne.channels.get_builtin_montages(). IfNone(default), the channel positions will be removed from theInfo.- match_case
bool If True (default), channel name matching will be case sensitive.
Added in version 0.20.
- match_alias
bool|dict Whether to use a lookup table to match unrecognized channel location names to their known aliases. If True, uses the mapping in
mne.io.constants.CHANNEL_LOC_ALIASES. If adictis passed, it will be used instead, and should map from non-standard channel names to names in the specifiedmontage. Default isFalse.Added in version 0.23.
- on_missing‘raise’ | ‘warn’ | ‘ignore’
Can be
'raise'(default) to raise an error,'warn'to emit a warning, or'ignore'to ignore when channels have missing coordinates.Added in version 0.20.1.
- verbose
bool|str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.
- montage
- Returns:
See also
Notes
Warning
Only EEG/sEEG/ECoG/DBS/fNIRS channels can have their positions set using a montage. Other channel types (e.g., MEG channels) should have their positions defined properly using their data reading functions.
Warning
Applying a montage will only set locations of channels that exist at the time it is applied. This means when re-referencing make sure to apply the montage only after calling
mne.add_reference_channels()
- __hash__ = None#
- property cluster_centers_#
Fitted clusters (the microstates maps).
Returns None if cluster algorithm has not been fitted.
- Type:
arrayof shape (n_clusters, n_channels) | None
- property compensation_grade#
The current gradient compensation grade.
- property fitted_data#
Data array used to fit the clustering algorithm.
- Type:
arrayof shape (n_channels, n_samples) | None
- property labels_#
Microstate label attributed to each sample of the fitted data.
- Type:
arrayof shape (n_samples, ) | None
- property random_state#
Random state to fix seed generation.
- Type: